Shared Assignable; the best of both worlds? September, 2006
When architecting a SaaS there are two ends of the spectrum when it comes to a data strategy; a shared multi-tenant schema where there is one database in which all tenants reside, then on the other end there is the isolated multi-tenant approach where each tenant has his/her own database in which schema can vary. In the whitepaper "Multi-Tenant Data Architecture", the SaaS guys at MS describe the options as a "continuum" between these two sides (Which include a number of other important factors but I will focus on the data strategy in this entry). I think that's a great way to describe the architecture options, especially since both ends of the spectrum can be mixed to provide an optimal solution. In my analysis of the options I don't see either end by itself as being optimal. Let's look at a few of the pros and cons (This list is by no means all inclusive!):
- Shared
- Pros
- Ability to update the schema in one place and affect all tenants.
- Only one instance to support, less personnel.
- Only requires one server (Unless vertically partitioning), less hardware.
- Excellent economy of scale!
- Cons
- Can only update the schema in one place and thereby affect all tenants. (This is both a pro and a con!)
- Difficulty restoring individual tenant data.
- Can only scale up.
- Pros
- Isolated
- Pros
- Ability to update tenant schema selectively.
- Ability to easily restore individual tenant data.
- Ability to easily scale out.
- Cons
- Must update hundreds or thousands of instances to implement a schema change.
- Many instances to support on many servers, more personnel.
- Many servers to support, a lot of hardware.
- Poor economy of scale (Relative to Shared multi-tenant.)
- Pros
Like I said, definitely not all inclusive but does represent some of the major pro's and cons of each end of the spectrum. A little more about these issues:
- Schema updates – The shared approach is great when applying schema updates, once and you're done! This is especially nice when a bug is discovered or when delivering a new version. With an isolated approach the schema must now be applied to hundreds or even thousands of instances! Ouch, no fun at all! On the other hand, what if you are releasing a new version but only want to expose a few clients to it, not all of them? For the most part (Depending on the types of changes made) this is not possible in a shared environment. Everybody gets the changes. And if it turns out that there are major issues with this version it will affect all clients.
- Software support – In a shared environment software support is very simple (Relatively speaking... ;-)). Schema changes are applied to one instance, there is only one version of the schema to support, bug fixes are relatively straight forward. This requires less people to support. The isolated approach on the other hand has hundreds or even thousands of database instances and schema variations to support. Bug fixes are not as straight forward since not all schemas might be affected by a particular bug. Developing new versions of the application can be tricky since there can be many variations to the schema which the application will have to account for. On the other hand an isolated approach does allow you the latitude to make custom changes to the schema and accommodate individual tenant needs.
- Hardware support – Shared environment, one server, one database (Unless vertically partitioning), a lot less hardware to support. Bad thing is, for the most part, you can only scale up which can seriously limit your ability to handle more tenants or resource hungry tenants. Isolated environment, many databases (Possibly hundreds or thousands) and servers to support. This means more hardware and more support personnel. BUT, you can scale out very easily. A resource hungry tenant can be put on his/her own server and as more tenants are added more hardware can be added allowing you to have more customers.
- Restores – Shared, the restored data must be merged in with existing data. This can be difficult, especially if the system was not designed, with the ability to do this, in mind from inception. Isolated is obviously very simple (For the most part) since it will more than likely just require a single database restore.
In an attempt to get all the pro's and as few of the cons as possible, what if we used a hybrid approach. I will call it Shared Assignable. Basically the system and schema are architected from inception to be shared but support multiple databases which can contain one or more tenants. Tenants can be assigned to database instances through provisioning. This thought is described in the MS whitepaper mentioned previously under "Tenant-Based Horizontal Partitioning" as a scaling technique for a shared database (I would highly recomend reading the entire whitepaper!). Shared Assignable would have the following characteristics:
- Support multiple tenants in one database – Each database instance can support one or more tenants. This follows the shared tenant, single databse paradigm.
- Support multiple database instances – By means of meta-data, the system will support one or more database instances on one or more servers. Tenants are assigned to an existing database instance or to a new one during the provisioning process.
- Support multiple application instances – By means of meta-data a particular version of the application can be tied to a particular database instance. This enables us to run one version of the application for tenants in a particular database instance and another version for another instance. This is important for allowing limited release of a new version of the application.
- Support abstract data and schema identification – The data and schema will follow an identification pattern (Similar to implementing an interface on a class) that ties records and schema elements to an individual tenant. This allows the system to identify tenants and also to perform ETL operations on individual clients without being required to understand the full extent of the schema. For example, at a basic level, every schema element would begin with a "MyApp_" and every table will be required to have a "ClientId" column. In the event a tenant must be moved into another database instance for performance or size reasons, the ETL process can simply enumerate tables that begin with "MyApp_" and records that have a "ClientId" of 123. These can then be moved to the new instance without the ETL process having prior understanding of the schema other than the table prefix and "ClientId" column name. These ETL operations can be written once and not have to be updated to handle schema variances between instances or versions.
This approach allows you to group tenants much the same way you would group applications in application pools in IIS 6. For example let's say you have 1000 tenants. The following factors determining their usage (Again, not all inclusive):
- Feature exploitation
- Number of concurrent users
- Usage time
- Data size
As such, they can be classified as follows:
- Lightweight – Exploit a small number of features, low number of concurrent users, use the system for a small amount of time each day and do not have much data. Data can reside in a shared environment.
- Middleweight Shared– Exploit many of the features, moderate number of concurrent users, use the system during business hours, moderate amount of data. Data can reside in a shared environment.
- Middleweight Isolated – Same as above but data cannot be shared because of privacy and/or performance and disk space reasons.
- Heavyweight – Exploit all features and drive new features, high number of concurrent users, heavy usage around the clock because of global staff, large quantity of data. Data can not be shared because of privacy and/or performance and disk space reasons.
With that classification let's say that 800 of those tenants are lightweight, 195 are middleweights 145 of which can be in a shared database and 50 that cannot. And 5 are heavyweights. The isolated approach would produce 1000 separate instances. Since we are obviously "catching the long tail" as seen with the tenant numbers above, we would seriously be loosing economy of scale with the isolated approach. Plus since more than 80% of our clients have very low hardware requirements we would be throwing away those resources which are cutting into profit margins and could be focused on the heavyweights. Schema updates would be expensive as well. The shared approach would be challenging too, schema updates would be a cinch and we would have great economy of scale but our higher end clients could potentially scuttle our hardware as a result of their resource requirements. The Shared Assignable architecture however would in many ways give us the best of both worlds. The following illustrates how we could architect our SaaS data with the above scenario:
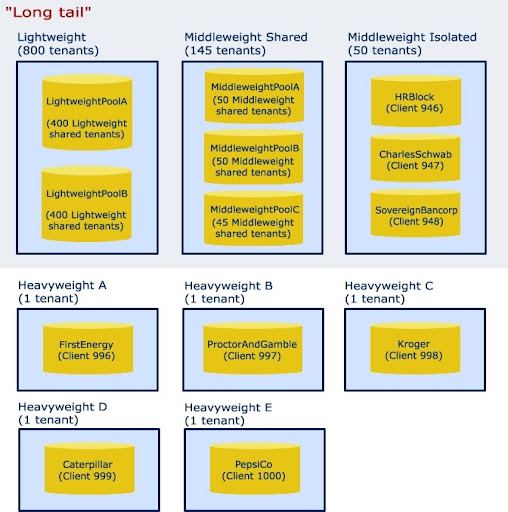
In this architecture we are appropriately distributing our resources so as to make the most of them. We are giving more to those who need it and less to those who don't. We are also not creating a high maintenance environment for smaller tenants which do not require it. In this example we are spreading 60 databases across 8 servers. In a purely isolated environment we would be dealing with 1000 databases over many servers. In a strictly shared environment we are dealing with one server, one huge database. Both scenarios would be very difficult to maintain and scale.
When creating a new tenant our provisioning process will give us the ability to add the tenant to an existing database instance or create a new one. This will allow us to judiciously place the tenant according to their needs and our architecture. Gianpaolo Carraro made an excellent observation in regards to service levels in this type of environment. By giving the provisioning process the ability to provision a tenant in a shared database or isolated database, on a shared server or isolated server we are enabling a pricing structure for the service. A silver package could be a shared instance, a gold package could be an isolated instance on a shared server and a platinum package could be an isolated instance on a standalone server. This allows you to offer a package that best suites the customer and recover costs for the services rendered and resources used.
Using meta-data we can also tie databases instances with a particular application instance. For example let's say that when we make a major release we only want to release it to one instance in our middleweight pool. The meta-data can direct requests for tenants in that database instance to use the beta version of the application. All other tenants would use the stable version. This mapping would only be available per database instance since the schema is tied to a particular application version.
Lastly, it is key that tenant data be easily movable thus allowing it to be "Assignable". It is inevitable that we will want to move tenants around as needs change and as the tenant base grows. This can be easily achieved by implementing an abstract identification schema on all database objects owned by a tenant. One way to do this is define object prefixes. For example all tables in our app could be prefixed with a "MyApp_Client_". This could tell any ETL process in our system that this is a "My App" table that contains client records. Secondly we will need to include a client identification column in all client tables, for example "ClientId. Obviously this will be present by virtue of the fact that we are using a shared schema but it will need to follow a set convention in all tables. In other words it needs to have the same column name and data type across all client tables. In an ETL process that moves a tenant for example, we could provide the tenant we want to move and the server/database we want to move it too. The ETL process could then grab all tables that begin with "MyApp_Client_" in the source database and all the records in those tables that have a ClientId of xyz. Our ETL process could then move these records into the target database. In the case where the system allow additional columns to be added to a table, the ETL process can dynamically detect these from the source table and add them to the target table. It is also noteworthy that the base data schema be metadata driven to allow the provisioning process to create new databases either for a new tenant or one that is moved into a new database. Plus it is required for schema upgrades. But that's a whole other can of worms... ;-)
 Bender (51 )
Bender (51 )